

KMW Technology
7 Videos
















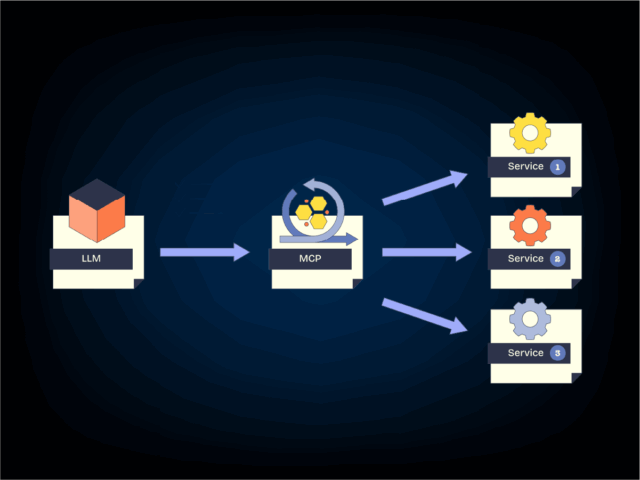
As with any tech decision, the right tool depends on the context. But as LLM development matures, the trend is clear: we’re moving toward simplicity, agility, and tight integration.

We describe the process of using retrieval-augmented generation (RAG) to create a question-answering system about Solr and OpenSearch using an assortment of LLMs from HuggingFace and OpenAI.

In Lucene-based search engines like OpenSearch and Solr, keyword aggregations ignore duplicate values that occur within a multi-valued field. We built an OpenSearch plugin to overcome this limitation.